

Масштабируемая архитектура UPA
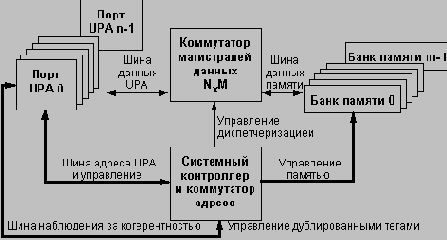
Отход от традиционных методов построения мультипроцессорных систем, основанных на наблюдаемой шине или на справочнике, позволяет существенно минимизировать задержки доступа к данным благодаря сокращению потерь на обработку промахов кэш-памяти. В итоге архитектура межсоединений UPA позволяет полностью использовать высокую пропускную способность процессора UltraSPARC-1. Максимальная скорость передачи данных составляет 1.3 Гбайт/с при работе UPA на тактовой частоте 83 МГц.
Разработчики архитектуры UPA многое сделали с целью минимизации задержек доступа к данным. Например, UPA поддерживает раздельные шины адреса и данных. Именно эти широкие шины (адресная шина имеет ширину 64 бит (в соответствии со спецификацией 64-битовой архитектуры V9), а шина данных - 144 бит (128 бит данных и 16 бит для контроля ошибок)) обеспечивают пиковую пропускную способность системы. Наличие отдельных шин позволяет устранить задержки, возникающие при переключении разделяемой шины между данными и адресом, а также возможные конфликты доступа к общей шине.
UPA не только поддерживает отдельные шины адреса и данных, но позволяет также иметь несколько шин с организацией соединений точка-точка. Обычно в большинстве систем имеются несколько интерфейсов для обеспечения работы подсистемы ввода/вывода, графической подсистемы и процессора. В мультипроцессорных системах требуются также дополнительные интерфейсы для организации связи между несколькими ЦП. Вместо одного набора шин данных и адреса для всех этих интерфейсов UPA допускает создание неограниченного количества шин.
Подобная организация имеет ряд достоинств. Наличие нескольких наборов шин позволяет минимизировать количество циклов арбитража и уменьшает вероятность конфликтов. Системный контроллер несет ответственность за работу и взаимодействие различных шин и может параллельно обрабатывать запросы нескольких шин. Он позволяет также уменьшить задержки, связанные с захватом шины. По существу, наличие нескольких шин адреса и данных означает меньшее число потенциальных главных устройств на каждом наборе шин. Для обеспечения наименьшей возможной задержки захвата шины используется распределенный конвейеризованный протокол арбитража. Каждый порт UPA имеет собственные схемы арбитража, при этом каждый порт в системе видит запросы шины всех других портов. Такая схема также позволяет уменьшить задержку доступа и обеспечивает увеличение общей производительности системы.
Архитектура UPA легко адаптируется для работы почти с любой конфигурацией системы (от однопроцессорной до массивно-параллельной). Разработчиками были предприняты специальные усилия с целью ее оптимизации для систем, содержащих от 1 до 4 процессоров. В результате до четырех тесно связанных процессоров и системный контроллер могут разделять доступ к одной и той же системной адресной шине. Однако на базе богатого набора транзакций и протокола когерентности, которые поддерживаются устройством интерфейса памяти процессора UltraSPARC-1 могут быть построены мультипроцессорные системы с большим количеством процессоров. В архитектуре UPA применяется протокол когерентности, построенный на основе операций записи с аннулированием соответствующих копий блока в кэш-памяти других процессоров системы и использующий для наблюдения дублированные теги. Процессор UltraSPARC поддерживает переходы состояний блоков кэш-памяти, соответствующие протоколам MOESI, MOSI и MSI.
Следует отметить, что в основу архитектуры UPA положены настолько гибкие принципы, что она позволяет иметь в системе не только несколько шин (мультиплексированных или раздельных), но и в широких пределах варьировать разрядность шины данных для удовлетворения различных требований к отношению стоимость/производительность. При этом в различных частях системы в зависимости от конкретных требований может использоваться разная скорость передачи данных. Например, разрядность шины данных системы ввода/вывода вполне может быть ограничена 64 битами, но для согласования с интерфейсом процессора более предпочтительна разрядность в 128 бит. С другой стороны, разрядность шины данных оперативной памяти системы может быть еще более увеличена для обеспечения высокой пропускной способности при использовании более медленных, но более дешевых микросхем памяти (в младших моделях компьютеров на базе микропроцессора UltraSPARC-1 используется 256-битовая шина данных памяти, а в старших моделях - 512-битовая).